Highlighted Posts
-
No Car Challenge
2026-04-03 17:23:30 PDT
I write about a challenge I made for myself: not using my car for a week
-
Along our Northern Border
2026-01-26 14:16:23 PST
I share my journey to Port Angeles Washington
-
17 Miles Outside of Alturas
2024-07-06 19:11:44 PDT
I talk about my journey to a plot of land I purchased, and the bitter realization that met me shortly after I arrived.
-
The Garden
2023-06-07 01:00:00 PDT
This was a little narrative I wrote one day going over a day in my garden and thoughts that filled my mind on that day
Recent Posts
-
Expand Text
2026-08-01 00:57:35 PDT
We've switched to a new ticketing system at work
Being the luddite I am, I hated it.
We were using Zendesk before and it was fine. Before the company really started growing and it was just me and a couple of other guys managing all the tickets, we had a pretty good, albeit informal system for managing tickets. It was messy and lacked cohesion; we all had our own barometers for what counted as a pending vs open ticket, but once you learned everyone's peculiarities, it ran fine.
Then we started growing, throwing in another layer of management, meaning a new director and a name change for our department. Don't get me wrong, he's a nice guy, but the new director was obsessed with ensuring we had a strong ticket routing system that was entirely unified. I get it. From an outsider looking in, our existing "system" was unideal, but it worked.
He revamped our Zendesk to now have all these automated routing features; calls also now created a corresponding ticket so there was a searchable record and summary of what was done. The routing features didn't really apply to me, as I was the only one active for the night shift, but nevertheless it got in my way. New conversations would get assigned to me with a little notification that I always managed to miss. Then I'd be waiting on the Unassigned tickets page watching for something new to come in the queue as the student was waiting for my response, as I sat none the wiser. Eventually they disabled the phone-generated tickets because they filled the ticket queue with junk calls or students looking for another department. The "optimization" really only served to slow us down. I found my ways around it. Marking myself as "busy" kept the tickets flowing into the unassigned queue, preserving my workflow.
Then the switch to Kustomer happened.
The first week of rolling it out was one of my worst weeks at work. I was simultaneously fighting with the new system and trying to get through the mountain of tickets that was piling up. Most things were 1-to-1 with Zendesk; you snooze a ticket instead of marking it as pending, a ticket is "resolved" instead of "solved"; those were easy to understand. What threw me for a loop was the asinine UX. Visually, it's prettier than Zendesk and has an actually functional dark mode. However, EVERYTHING is hidden in a submenu or tooltip, instead of displaying all the customer information in a column on the side of the chat like Zendesk. You have to hover over their name for the tooltip of their email to appear, and you better not take too long to move your mouse, because the tooltip will automatically close if you're slower than Usain Bolt. This sounds like a nitpick, but when you're constantly copying and pasting emails, which is 90% of my job, that little bit of friction is a real delay. Not to mention, I only found it by accident, so for the first few days I had to open the customer info submenu. My pace and rhythm were all thrown off, things that should take 5 minutes took 15 because the other 10 were spent fighting with our new system. More were coming in than I was able to complete and by the time they arrived in my inbox, the student had already left. Instead of forwarding new chats that had just come in, it was sending me thermostat requests from 9:00 in the morning.
Not to mention the problem of calls was back! Again, every phone call we received came up as yet another ticket clogging the arteries. I found a fun bug where I couldn't hear what the person on the other end was saying, but it showed up fine in the call recording. In addition, half the time I wasn't even aware we were getting a call because the ringer that plays is so quiet and the only visual indicator is a tiny pair of buttons that appear in the bottom right of the page. I was able to convince the director to only have it create a ticket if they left a voicemail, but even today I missed a couple calls even when I was staring at the screen.
That first week was awful.
By Wednesday of the following week, we had all gotten a bit more accustomed to the new system and we had burned through the rest of the pile. Now, I was able to play around a bit more with it, without feeling the need to rush. Kustomer is pumped full of slop. For every action, there is an AI integration, automated summary, or sentiment analysis. Most of it is useless. Its hallucinations in the hand-off summaries require you to read through the chat history anyway.
I noticed it had a pair of buttons in the chat box: "Fix Spelling" and "Expand Text". Fix Spelling is self-explanatory, but I was curious about the other option. I had a hunch it would flesh out a message, but wanted to see how it worked. So I typed my usual response, then pressed the button. After a few seconds of waiting, I was greeted with a wall of text, mostly containing filler. It was riddled with "I understand you are having a problem with XYZ", "I understand how frustrating that can be", and "If you have any questions, please feel free to ask! I'm here to help". At first I rolled my eyes, but I continued to test it out, to give it a fair shake. The more I used it the more I came to like it. Instead of spending a minute typing out a curated message, I could type "I ordered your replacement and sent a return label" and it would fill in all the rest.
This honestly has been a bit of a game changer in terms of my irritability levels. Nothing drives me up the wall more than pretending to be nice to an asshole. Now, I type the bare minimum to keep the AI from hallucinating, let it fill in the pleasantries, proofread to make sure it hasn't repeated itself (it insists on needing to remind them we're here to help in every message), and press send.
The niceties have always been a bit of a pain point for me. In the past, I've gotten a couple emails from my boss saying that the CEO was reviewing recent tickets and he didn't like how I handled something, not on technical merit, but because I didn't bend over backward to blow smoke up the student's ass for being so smart to reach out to us. I just tell them what they need to do to get their tech working and tell them to have a great rest of their day.
It's made me reflect on how much of communication today is made up of "expanded" text. Every job listing I read contains a short novel about how each company is a family trying to build a better world. Every studio movie is long and drawn out, pumped full of lines to say exactly what the character is feeling at all times. Every email could have been handled in 2 sentences, but is padded out to 2 paragraphs. And it's always that sickening overly-enthusiastic faux-friendliness that makes you feel like you're trying to be sold something.
There's a reason why AI psychosis is a problem. The trainers of these bots make sure every question you ask is answered with points about how novel, insightful, or brilliant you are. It's so people feel good while using them.
I wonder how much of our culture has been shaped by marketing teams and sentiment analysis. These tools existed before AI was big, and now it's pervasive. If they found that beating people over the head with niceties resulted in a 10% higher satisfaction rating, and made it company policy, how long did it take to seep into the vernacular, and how long does it take to spread? Will we have to pad every conversation with reaffirmations that the other person is doing a good job?
Probably not.
I know I'm not the only one who is irritated by this sort of thing. In fact, a number of students have thanked me for just being direct and getting their problems solved efficiently. After dealing with the other departments and their "enthusiastic" messages, I understand why.
We just want to talk like humans, not chatbots
-
On AI 2: Agentic Boogaloo
2026-07-11 00:39:21 PDT
I initially underestimated AI
Two years ago I wrote On AI, in which I concluded AI was "kinda cool, useful in a number of scenarios, but not the major step forward in humanity that it's being made out to be". Today, I'd say it's very cool, useful in many scenarios, and a somewhat transformative technology.
This wasn't a position I had come to overnight; it came to be little by little as tools improved.
The web chat clients for the models were a good first step, but were limited by the medium. At this stage, I found it most useful as a search engine / example generator. It was good for getting a direct answer to a question instead of being handed a full field manual that would trail off course every few pages, like traditional search results. Granted, the answer it gave was not always the best answer, or even correct, but it was decent and it saved time. Needing to copy and paste everything in and out is the kind of friction that hurts the overall usability, especially in programming. Sure, you can copy and paste each file it potentially needs, but as files get modified, the model's understanding drifts away from the ground truth and the goal gets lost in a jumbled sea of context.
Then 4 or 5 months ago I gave Claude Code a try. My first session with it was the moment I knew that this technology was going to last long after the bubble pops. Being able to read the files directly and run commands minimizes the time wasted on menial work. Refactoring code now meant writing 2 sentences, waiting 30 seconds, and verifying the bot didn't hallucinate. Most of the time it's been spot on.
There are many different levels of AI-assisted programming. I have been guilty of all of them. I say guilt because I mean it. It does feel a bit cheap to offload the labour of thinking to a robot, but then again, this is essentially what programmers do whenever they import a library: offloading cognitive labour. Nevertheless, it feels like cheating. Then again, I've never been able to accomplish so much in such little time.
No matter the craft, there is pride in practicing it in a manner closest to the root. There's a spirit to a hand-carved piece of furniture, imbued with the soul of its creator, one that is simply not found in one assembled in an Ikea kit. It is the same with AI. You can spend hours working out how everything goes together, how each callback function ties into the next. It is deeply rewarding to see it all come together, spring to life, and serve its purpose. But sometimes you don't need an elegant statement piece that ties a room together; you just need a coffee table to put your mug on.
That is generally how I approach AI use in my projects, first with asking myself how much I care about the end product. If it is a script for work, I don't even open up the text editor and just vibe code the whole thing. If it is a tool I'll be using day in and day out, I'll still keep Claude open for debugging, but will be far more involved and will instruct it to not make edits on its own. That makes it feel a bit more like my own work and not "prompt engineering".
For the past year on Linux Unplugged, Chris and the gang have been exploring AI tools, much to the chagrin of some of my fellow listeners. They tried out OpenClaw when it first hit the scene back in April. When I first heard of it, I rolled my eyes. Of course the headlines were all around people putting them on their own agentic social media platforms. I thought it was just another tool of the week, that the show would move on to another one and leave it as a faint and distant memory, but Chris began integrating it into everything. Each new episode he would share how he had automated, fixed, or created something with it.
It piqued my interest.
However, if I was moving away from Claude, its replacement was going to need to have some major benefits. Being the paranoid person I am, I wanted to run something locally. In addition, as I have mentioned before, I have been wanting a Mac of some sort to keep using Openbubbles whenever I eventually leave my job. So the natural conclusion was to get an Apple Silicon Mac. They're efficient little bastards that allegedly are great for running LLMs.
I set a $200 budget and hunted Ebay, Craigslist, and Marketplace for any beat-up M series. I ended up winning at auction a 2020 13" M1 Macbook Pro with a horribly cracked screen. For a week, I eagerly waited for it to arrive in the mail, researching what models would be best suited for it. I didn't have high expectations for it, figuring Claude is at least 4 times faster than whatever I could run locally and would probably make more mistakes. That didn't matter though; it was going to be on my hardware and that was worth the trade-off! Right?
HA!
I unboxed it, struggled to get it to use an external display for half an hour, then got logged in. I set it up to be as headless as a Mac could be, fighting Apple's permissions dialogs every step of the way.
After some more faffing about, Ollama was installed with one of the low-end Qwen models, and so too was Hermes on my laptop.
I eagerly typed: "Give me a weather report for Sacramento and Port Angeles, WA for tomorrow".
45 minutes later
Sacramento weather:
86 degree high, 0% precipitation
So that was a bust...
Too slow and too stupid to be of any use to me. Hermes is just about the worst thing to use this low-end of model and device for, with its heavy use of memories and skills clogging up the minuscule context window. I continued to try and make any tweaks I could, but you can't make a weed-whacker motor a big block V8, no matter the amount of tuning. I put the Macbook back up for auction less than 24 hours after it left the box.
I still wanted to try out Hermes and so I followed in Chris's footsteps and threw $10 into usage credits with Deepseek.
Once it was all wired up, I just started playing around. I stared in amazement as it navigated through my network, learning its surroundings, taking notes on its every finding. Within minutes I was able to refer to each of my computers by their hostname and have the bot be sshing in to do whatever task I needed. In an afternoon I had unified all the shared configs across my boxes to be pulling from a unified source of truth from my local git server. With a little minion to do my bidding, all the annoying tedium has become one request away.
Over my brief time using Hermes, it's easily taken the place of Claude. Even though it isn't as smart, it makes up for it in its note taking. If it makes a mistake, it makes it once. As soon as you correct it, the solution is stored away in its memories without needing to explicitly tell it to.
One thing I'm kinda grateful for is that it isn't an amazing code-writer. It's able to read code fine, and generate usable documentation better than I could, but it kinda falls flat on its face if it needs to write more than 20 lines. This has made me use it more like I did a year ago, using it for a documentation finder and tedium minimizer. It'll make the jigs, while I get to focus on the craft.
Even if the models themselves have only marginally improved over the past 6 months, the tooling around them is maturing and widening their capabilities.
Of course, to many people this is grim, sickened by the pervasive sprawl of AI and slop. Now we're supposed to have them run amok on our computers? I have sympathy for them, as I wasn't a big fan of it originally either. I remember losing all faith in humanity when my Uber driver pitched his AI therapist app to me. The only thing I can say to them is that AI is a tool.
A hammer can both be used to build and to destroy. A car can unite families for a holiday, or wipe them out in less than a second. The internet united the world and divided nations.
No technology is without sin.
-
The USA at 250
2026-07-06 14:23:14 PDT
Saturday was our nation's 250 year birthday!
Of course, that's counting from the signing of the declaration of independence, fighting had been occurring for over a year and we wouldn't have our constitution for another decade. Even then we wouldn't have the supreme court in its modern understanding until 1803, nor the central role of the federal government until after the civil war. There are countless moments in our nation's history of major paradigm changes where you could say it was reborn.
As I've grown older, I've come to appreciate the garish Americana that rolls out this time of year; with one trip to an all-American big box store you can be adorned with stars and stripes prints on every article of clothing and accessory. At a certain point I realized it's all part of the joke. We are obnoxious Americans and we are proud of it, slap our flag on everything; nothing else rivals its beauty.
This time honored tradition is one thing that unites us. For the past few years the 4th has been bittersweet. Sure you'd still have a party, you'd still watch the fireworks, but you'd try your best to not think about the state of our country more than you had to.
However, this year felt a little different. Maybe it's just because we are doing a bit more flag-waving with my girlfriend in the Coast Guard, maybe it's just because it's the 250th, but people seemed a bit more patriotic this year. Definitely not because of our commander in chief or his cabinet, even the true believers are waking up. I think everybody is getting their head back on, COVID and its consequences made us all go a little crazy, some more than others. Everybody knows we're in it deep, and if we don't start acting rationally, the country won't reach its 275th anniversary.
While I don't love all his policies, the rise of Mamdani nevertheless has given me hope. He's a leader who is willing to take action, to get things done, he's been able to reach people by communicating with them. Not talking down from an ivory tower, but speaking to them directly, with dignity and respect.
But above all else, what has given me hope for our nation, has been my girlfriend and her family. Being involved with a first generation family, I've gotten to see the actualization of the American dream. A dream which I once thought was dead. A family traveling thousands of miles with only the clothes on their backs, entering into a foreign land with a different language, doing their best to persevere, and succeeding; it's a beautiful thing to witness. I believe if you took even the most xenophobic of people, had them live as a fly on the wall, had them see the character, the good hearted nature, the open armed generosity, and civic pride that this family has, and thousands more families like them have, then they too would admit that they embody what it means to be an American -- more than many of us who were born to this soil so too could claim.
It's not morning in America. In fact, we're in the dead of night, but again the sun shall rise.
-
The problem isn't going away
2026-06-22 12:42:23 PDT
Technical illiteracy in the general public is a problem us in IT are well and familiar with.
Now before I start complaining about other people, I first want to do some throat clearing.
I do not expect everybody to understand everything their computer does or how it does it. I don't think most people's thought of a good time is setting up a new service on their home server, even if I do (and if you read this, probably you do too).
What I'm trying to say is that I think it's ok if you aren't a computer whiz and choose to put your short time circling the sun into other interests and skills.
However,
It's sometimes infuriating having to help people who are technically illiterate. The number of people who I have run into that don't know what an internet browser is, despite communicating with me on our website is worrying.
From the moanings and groanings both online and in person from those of us who have to come to the aid of the illiterate, the sentiment "This problem will be gone when they all die out" is often heard.
Of course, I cannot insist the emperor isn't naked, the boomers are by and large completely helpless behind a keyboard. Though, I do have a bit more patience with them. They lived their entire lives, built careers, raised families, and then computer knowledge became a requirement to function in the workplace and society. In my experience they are pretty capable with basic office tools, word processing and spreadsheets, but flail when having to work with anything web-based.
Over the past 2 years, working with adults of all age ranges, I've realized this problem is not going away any time soon. In fact I'd say the tech illiterate of gen Z are as bad as the boomers. They have the inverse problem to that of the boomers, they only know how to use a browser. This gets them a lot further than the boomers in most tasks, but when they have to move data off of one platform and onto another, they too begin to flail.
When they are on a single platform, they are pretty capable once they are taught the basics. It's just that most institutions are not on a single platform. Trying to explain to them that what's on the cloud is not on their personal device is a labour of love. This is partially the fault of platforms, obfuscating ways to get your file out of the web-app. File -> Save no longer saves the data in the universal format, it saves it as the platform's project file. On Google Docs, it is the .gdoc file format, if you want it as a pdf or docx you have to select "Export". The web-app version of Word is even worse, just popping up "your changes are automatically saved", like no shit just give me the damn file.
There was just an assumption that kids would learn computational skills through osmosis, and for some time I think this held true. The 2000s were a time where it took some skill to operate a computer, and with the youth being interested in the online world, they picked up these skills. In the 2010s, when computing shifted towards a mobile-first paradigm, when ease of use became the guiding principle, the barrier of entry was lowered, and these fundamental skills were lost. Users no longer needed to do any real file management. Since mobile apps give the user little-to-no recourse if a problem occurs, when these users then are faced with a problem on a web-app or desktop native application, they don't have the tools to attempt troubleshooting it themselves.
This is almost entirely conjecture, but in my experience it is true. These kids come to me saying that the page didn't load, I tell them to refresh it, and amazingly it loads. Their older counterparts often at least tried to close the app and reopen it before they come to me.
There is job security for basic IT beyond the reign of the boomers
-
Save your files
2026-05-26 21:39:42 PDT
It's one of those rules that is repeated ad nauseam
I've been working on a post on and off for about a week or so.
I made a good chunk of it tonight at work.
Then my laptop died.
I thought to myself "No worries, I'll just recover from the swap file".
For whatever reason, the only one saved was from last week.
Now the inspiration to write is dead.
So always always always save.
-
My System Setup
2026-04-30 14:40:02 PDT
I've been using Linux for almost a decade now
I remember first installing Linux Mint on that crisp September evening in 2016 like it was yesterday; the wonder that came with a whole new landscape of software and paradigms. Once I had the first taste I couldn't have enough. I spent a sizeable portion of the following 5 years distro-hopping trying to find what felt right. I explored the debian-derivatives, the arch-derivatives, arch (which was my home for a long time), OpenSuse, Gentoo (did not last long), Artix, Devuan, and Void, probably missing some, but those are the major ones.
I ended up on:
Void
It's stable between updates, has great package availability in the official repos, and ships minimally customized versions of upstream packages! Also, it has its own init system, Runit.
I admit, I often can be quite contrarian, sometimes to a fault. When I first switched to SystemD-free distros, it was purely out of blind belief in the SystemD-hate spread online. Some of the arguments were valid, but a good chunk of which simply were not. I have gained respect for some of the added utility that SystemD brings, but after living in both, I still prefer Runit over SystemD for my day to day machines. OpenRC is also pretty good but a step down over Runit. The simpler systems just get out of the way and let me do what I want to do, where it feels like I have to jump through hoops for SystemD. If I want to create a new service with Runit, all I have to do is link a directory with an executable in it called "run" to /var/service. No need to figure out which settings I need to modify in the .service file, reload the daemons, enable the service, look through the logs for what went wrong, modify the .service file to fix it, rinse and repeat.
That's a general through-line with the software I like, it makes interfacing with itself trivial. The best exemplar is my window manager of choice:
Herbstluft WM
HerbstluftWM is a manual tiling window manager with the fun bonus of everything being configured through herbstclient, a program to interface with the window manager. This quirk ends up being HLWM's greatest strength, as it allows you to script just about every action. With a relatively simple tiling script that runs at startup, I can have the automatic window placement of a dynamic tiler, but with the flexibility of a manual one.

As you can see windows automatically are placed in a master and stack / fibonacci layout until 3 frames are present. After, new windows are added to the focused frame as a tab. However, you can still add new frames that go against these rules. The auto-tiling script won't kick back in until the windows are arranged in a way that matches the original tiling algorithm.
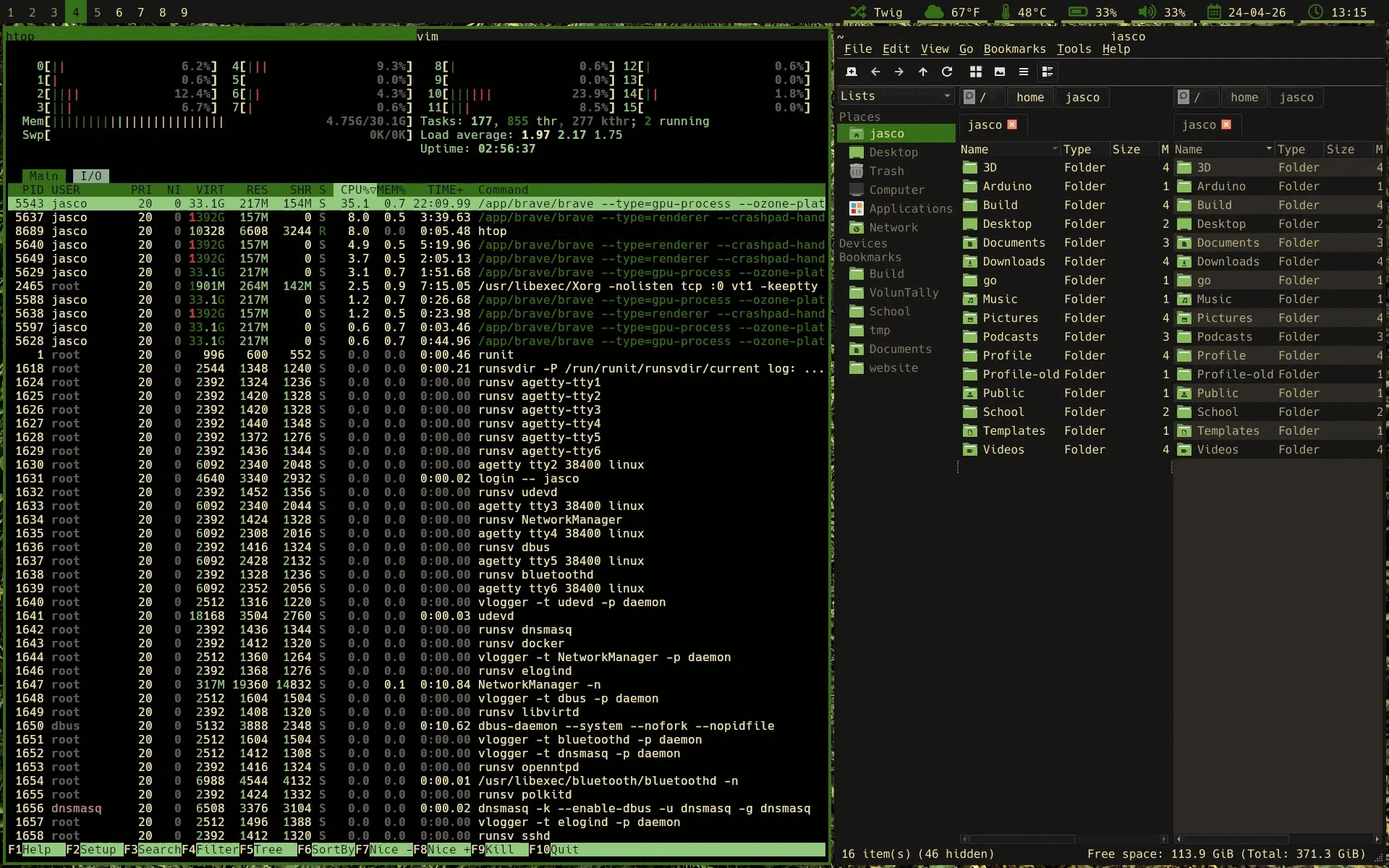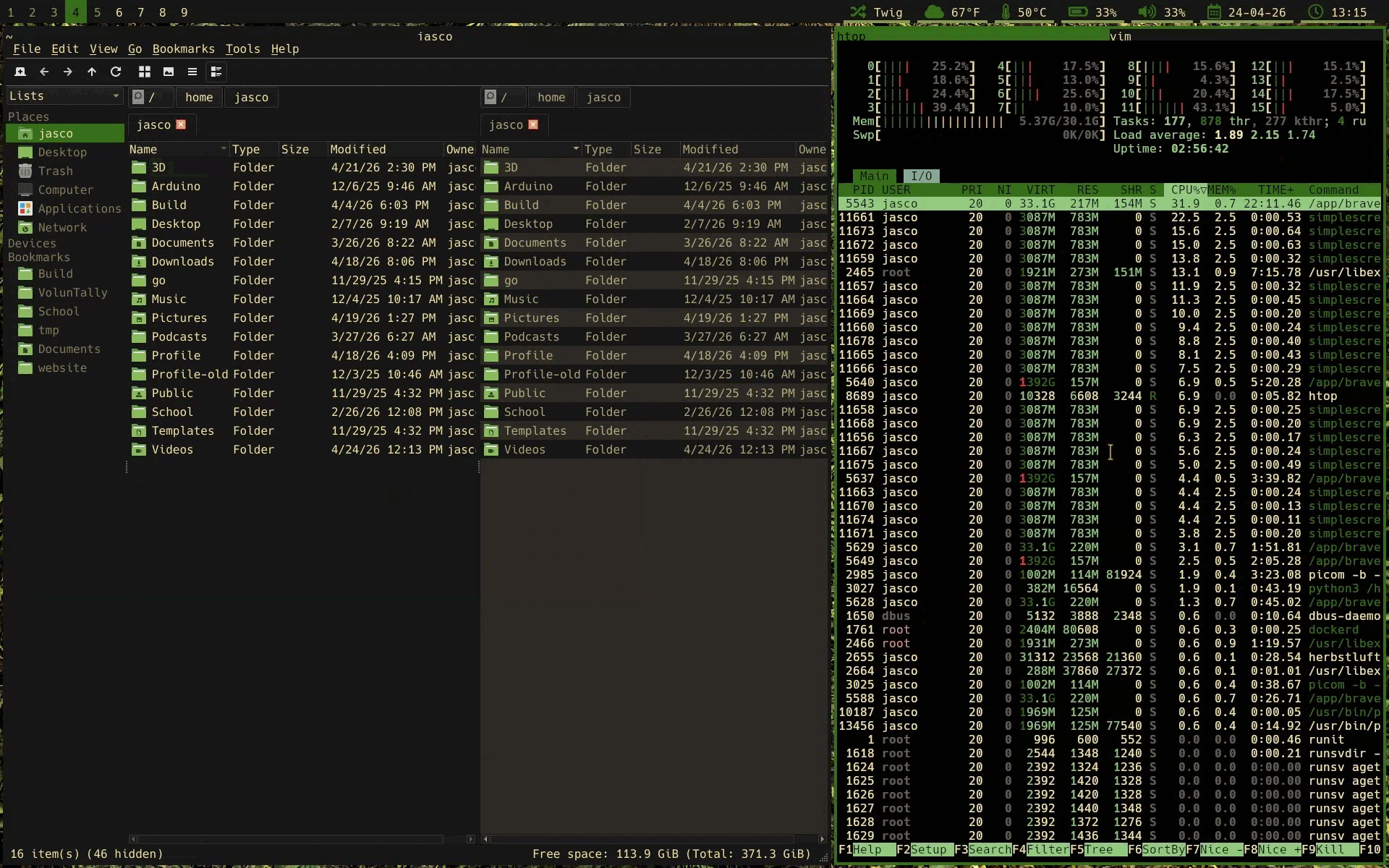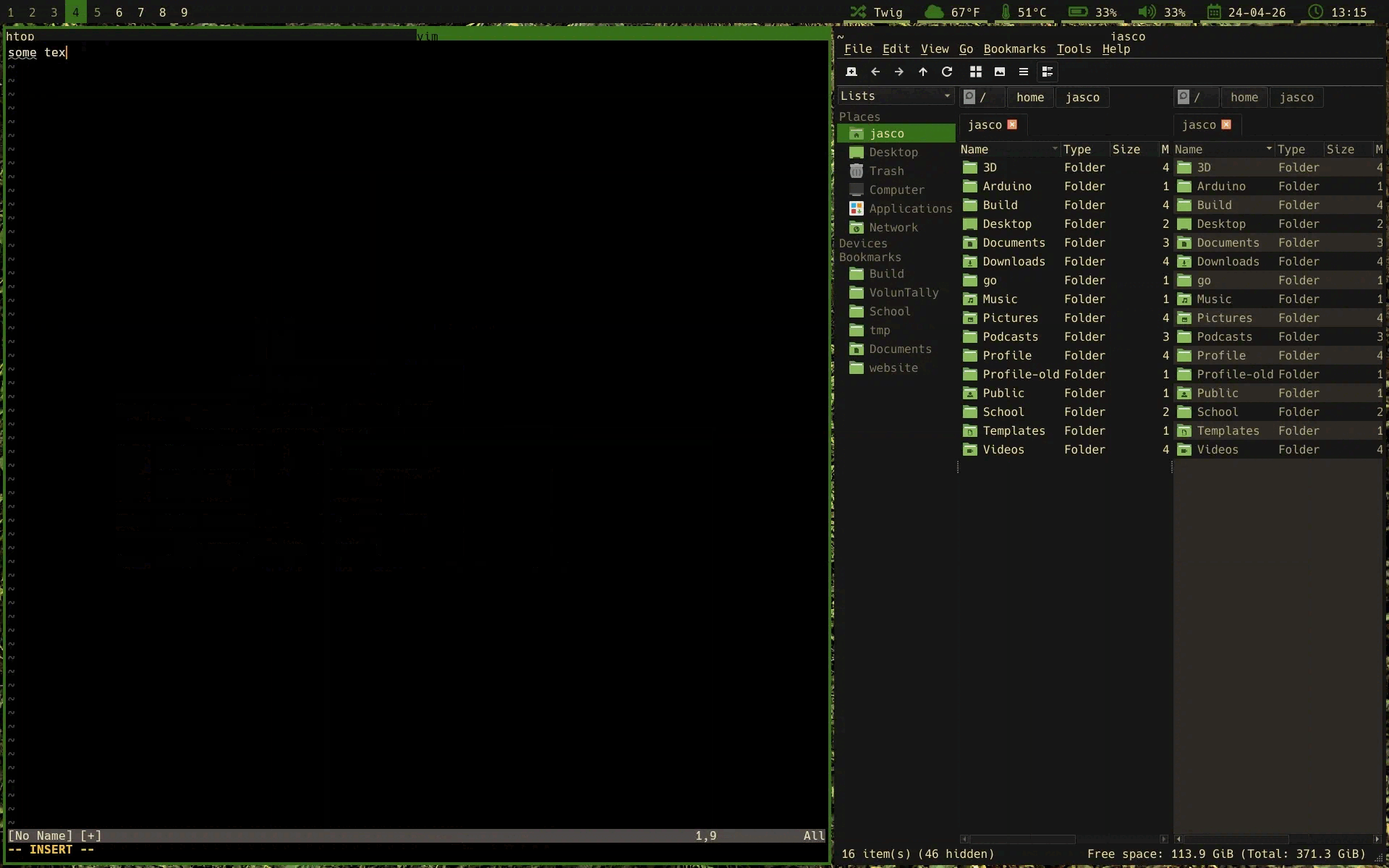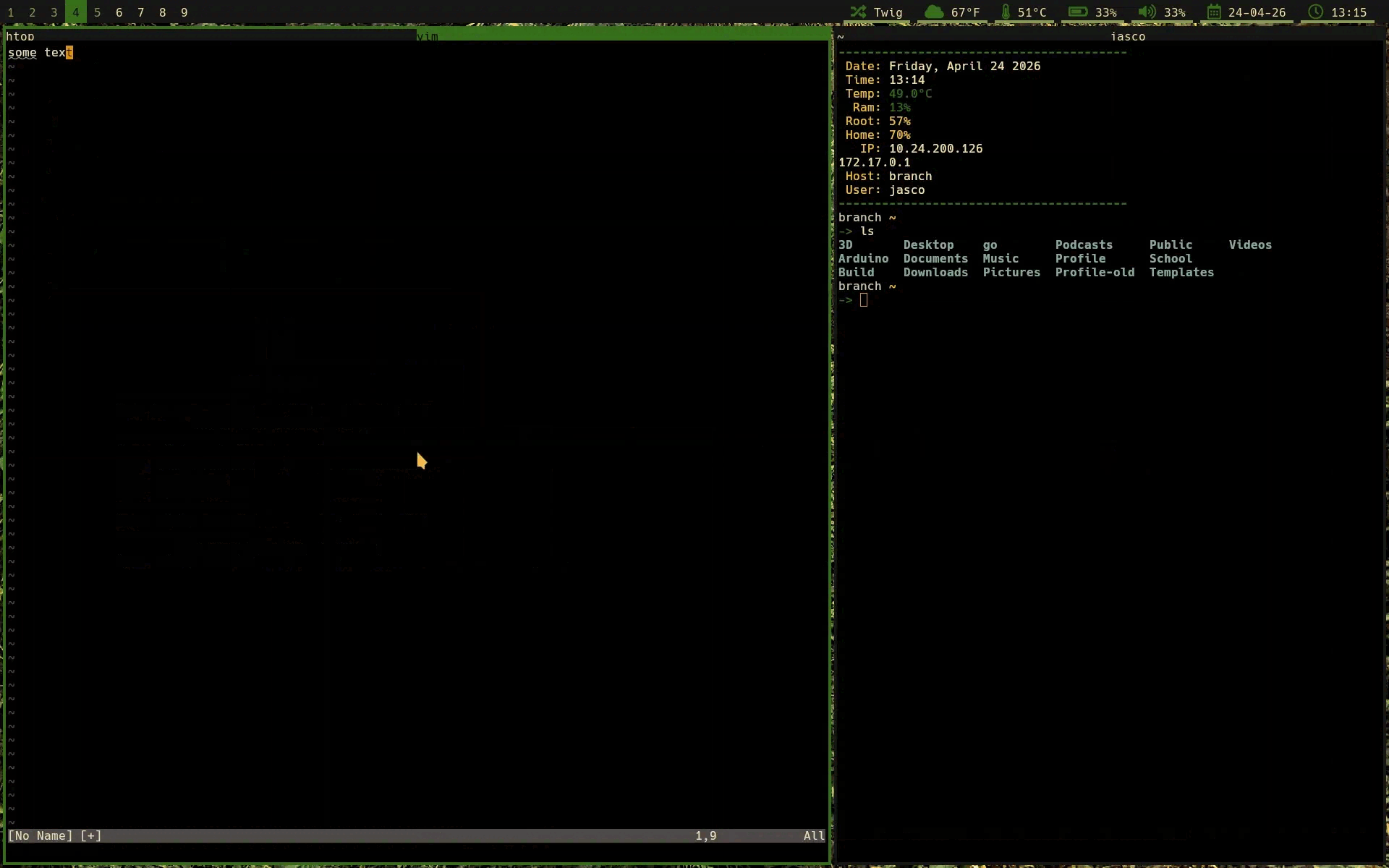
And I can swap frames as well, like most master and stack layouts allow.
With the tools HLWM gives you, you can create more complex window rules and build in complex functionality from simple operations, it's everything I want a window manager to be.
However, a lot of the time when I am using my computers, I do not want to be fiddling with all the little knobs and inevitable breakage that comes with standalone apps not behaving properly, which is why I run Herbstluft as the window manager within a desktop environment.
XFCE
Good ol' XFCE has never let me down. Even before I switched to tilers, XFCE was my environment of choice. It's not flashy, it doesn't try to be the hot new thing, it's just a modular DE that is easy to set and forget. This is one of the more recent changes I have made to my system, as I realized I already was using XFCE's services, such as their power manager and screen locker in my HLWM config. It just made sense to also get the niceties that come with a DE while preserving my setup.
Besides the more recent change with XFCE, this has been my setup for the past 5 years. Every now and then I would hop away for a week or two but I always ended up back here. However, I still like to tinker on my machine from time to time, but at a more granular level. Instead of nuking and paving, I like to make little improvements to the setup. My best example of which is the panel.
Lemonbar
For those who don't use tilers, it's common for standalone window managers to not ship with any panel/dock/taskbar built into them. HLWM is one of the ones that doesn't. Instead, you have to pick from one of the many standalone panels and configure it to display the information you want. I am using Lemonbar as it has a fairly robust method for aligning and styling text, and it simply will display what is sent to it from stdin. Like most of my scripts, the first iteration was very much hacked together, with hard-coded paths and commands. Over the years I have made various changes, making things cleaner, having it redraw intelligently, adding clickable shortcuts, all sorts of little tweaks.
It has evolved along with my programming abilities. Initially I was updating the bar's contents every 0.4 seconds, so that there wasn't too much of a noticeable delay whenever you switched workspaces, a very brute-force solution. This of course ate away at system resources and battery life, but functioned. Once I started actually needing to leave the house again, that brute-force solution wasn't cutting it. Fortunately, HerbstluftWM emits hooks for pretty much every event, so I was able to base the bar-redrawing off of that.
At some point, Windows started displaying the current weather in its taskbar. Not wanting to be one-upped in functionality, I added a weather widget. At first, via scraping wttr.in, but after it proved to be less-than-reliable, with Pirate Weather. Which in turn was once a hard-coded value for the location, but now fetches my current location from my owntracks server.

These are my current modules, Twig is the SSID of the current wifi connection.
Whenever I get bored and feel like tinkering, I simply try to improve or automate something in my config.
Reflections
I remember watching videos of people showing off their highly customized setups and having a longing feeling of wanting it for myself. Not to have their exact setup, but to have one that flowed with my stream of consciousness like theirs seemed to.
The mythical "end game" setup.
I would copy their configs, either in part or in whole, and expect everything to come naturally, like it did for them. Alas, it did not.
That's the nature of these highly customized setups, they're tuned to the designer's way of thinking. Maybe that is highly correlated to the way you think, and copying or mimicking his or her setup would work out.
The only way to know is to try.
-
No Car Challenge
2026-04-03 17:23:30 PDT
I received a phone call immediately after stepping out of the shower Monday afternoon
My supervisor told me that since our in-person classes are off this week it didn't make sense for me to come into the office and that I can work from home if I would like.
Naturally, I obliged. No sense in driving 45 mins to work when I can stay in the comfort of my own home, getting to wear whatever I would like. Plus our bird-brain in chief's war with Iran has brought gas prices into the $5 range, so less driving means more saving.
Part way through my shift I recognised I wouldn't need to drive at all if I didn't want to this week, and by week I mean up until EOD Friday.
Day 1 (3/30)
Seeing as I originally didn't plan on starting this challenge until nearly the end of the day, I have little of note.
Day 2 (3/31)
Man I need to get out of the house. I was back in WA this weekend, so getting some reprieve from travel was nice, but has now overstayed its welcome. I was meaning to take my bike to the store, but what I thought was going to be a 30 minute meeting turned out to be 2 hours. Then it was time for work and we were getting tickets at a high enough rate that I couldn't justify taking my laptop with me for a quick trip to the store.
The problem is, I started a new mini-project that ended up sucking me in. I've been trying Claude code and holy moly is supervised vibecoding fun. Suddenly those simple apps I have always wanted are far easier to build. I simply have to get the core functionality working myself, and let the bot write all the stuff that boils down to essentially boilerplate, while I get to fill out the core logic.
I wanted a TUI that I could use to quickly navigate through directories without needing to keep typing "cd ../../.."

Then I just asked the bot to make minor tweaks and I had exactly what I wanted.
Tomorrow I'm making a rule, I have to be outside for at least one thing before 11:00.
No sense in not using a car if you don't go anywhere.
Day 3 (4/1)
Today I drove my car... NOT haha April fools.
*crickets*
No today I held true to my promise of yesterday of getting out of the house before 11:00. Well... it was more like 12:30, but I got out of the house and that's what matters.
I didn't need much from the store, just some olive oil and laundry detergent, but while I was there I got some cheese and salsa for tacos. Somehow in 2026 that is $72. Now mind you I was buying the larger options, 32 fl.oz. for the oil and 132 fl.oz. for the detergent, but still that doesn't feel like that should be over $50.
The bike ride to the store was nice, there was a calming, gentle rain.
The ride back wasn't bad either, but man, even having fairly moderate weight cargo really does make pedaling a little bit harder.
Having that break from being in my room gave me just enough motivation to clean up a bit and toss out a lot of things I know I don't need anymore. I know I will be moving out of here before the end of the year and so the junk I have accumulated over the past almost 5 years living here is beginning to feel overwhelming.
Tomorrow I'm going to my girlfriend's family's house, which according to maps is a 1 hour bike ride. I am a little nervous since it's been some time since I've gone that far on a bike, but a challenge is called a challenge for a reason.
Day 4 (4/2)
Phew what a ride! ~24 miles round trip
I knew I was in for a treat when I felt some soreness from the short ride I took yesterday. It seemed like no matter how hard I pedaled I was not keeping much momentum. Then I looked down and noticed my tires were low on air... that would explain it. Fortunately, I was only about half a mile away from the university and they have pumps near all their bike lock-up areas, plus I was already going to pass through it to get on the bike trail. Once I filled up it was far more smooth sailing.
I was going to meet up with my girlfriend's sister. We got close while my girlfriend was away at boot camp and we try to hang out every week or two to swap family drama. Fortunately for me, her afternoon plans got cancelled so I wasn't in a huge time crunch to get there, but didn't want to leave her hanging either.
As I kept pedaling I could feel myself getting tired, but I tried my best just to pace myself instead of resting.
I made it to the house about 12 minutes later than what maps had originally estimated. The blame lies more with a wrong turn I made more than my pace, but it was not quite into the range of being rudely late.
Our chat was short, but nice. She asked about my trip and I asked about the goings-on of her life as we shared lunch. After the natural flow of conversation slowed we said our goodbyes and I was on my way back.
This leg of the trip was a lot calmer without the time crunch. I took a few water breaks and enjoyed the cool breeze.

Though pleasant while seated, the breeze was annoying while riding. It's amazing how just the little bit of extra resistance makes it feel twice as hard. As I got further away from the river, the breeze died down and I was back in the hustle and bustle of the intersection of 65th and Folsom. After a quick run to the store for some milk on the way back, I rolled into my neighborhood and felt eudaimonic.
The quick trips back and forth to the store are fun, but with this challenge I wanted to really see how different my life would be without using the car. This normally quick drive to their house ended up being an activity that took up the majority of the day. With our modern world being so hyperconnected both with the internet and with high speed transportation, it's easy to forget how big the world truly is. I had the same feeling over the weekend while riding on the Bremerton ferry to Seattle, watching the city skyline creep into view as the water lapped at the side of the boat.
There's a sort of peace of mind that comes with a car, you don't have to put any physical effort into going anywhere; you just get in your little box and go. Sure, it costs gas and different routes take longer, but a long car ride only will drain you mentally. Furthermore you're isolated from the outside world, you don't really have to worry about weather, temperature, or time of day, for the most part your car can adapt to nullify pretty much all these factors in a way you can't with a bike or on foot.
You just don't get the luxury of divorcing yourself from your environment.
Day 5 (4/3)
Much like how the challenge started, I don't have a need to leave the house today and thus don't have much to note.
I'm just happy I took the time to complete it, to do something just for the fun of the challenge. I may try doing more of these, so long as it doesn't interfere with the rest of life.
And I'm going to think twice before getting behind the wheel, when I can just as easily get behind the handlebars.
-
American English Spelling Mistakes
2026-03-27 05:54:39 PDT
Like any true American, I'm proud to not be British!
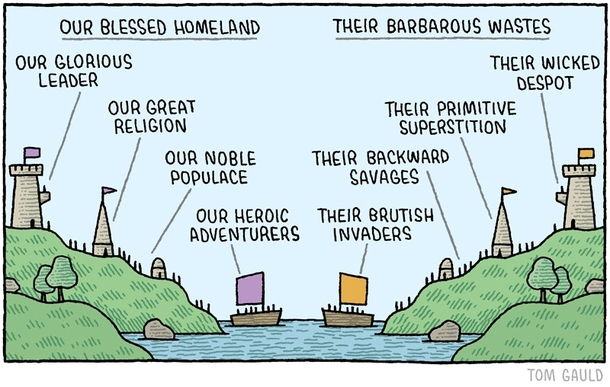
No hate towards our neighbors across the pond, but they are truly a backwards, barbaric people, with their lorries, lifts, flats, chips, jumpers, and trainers. There isn't a people more brutish than the British!
Us Americans, we are far more civilized, with our trucks, elevators, apartments, french fries, sweaters, and sneakers.
Naturally, we wanted to distance ourselves from those tea-drinking freaks and over time have adopted better spellings for the words we unfortunately share with them. However, in our noble pursuit of expunging ourselves of our englishry, we kinda threw the baby out with the bath water on a few of the spellings we selected.
In researching for this piece, wanting to give my readers nothing but the cold, hard facts, I discovered some other proposed spelling reforms by Noah Webster, the man largely credited for codifying American English spelling. Webster, a patriot, is the one we should graciously thank for fixing many of the obvious spelling blunders. However, he too made some mistakes, ones that thankfully never caught on:
- bread -> bred
- give -> giv
- women -> wimmen
- machine -> masheen
- soup -> soop
I mean the guy was a genius, but I can't read through that list without chuckling to myself.
English, like all other exports of England, will always be flawed. If we had a truly phonetic spelling for our words, that would be great, but would look terribly silly, and thus should never be done.
But first, the hits
-
centre -> center, theatre -> theater, metre -> meter, all the other re -> er words
Ok, this one is obvious. I know English is famous for its silent "e"s, but most of those are used for making a vowel long. Why on God's green earth would we ever put "re" when the word clearly ends in a "er" sound.
-
mould -> mold, plough -> plow, and draught -> draft
Oh you, "ou", such a versatile vowel pairing! Ayy you, "au", you ain't bad too. However, neither of you are welcome in the moldy draft beer I'm having after I plow the driveway.
-
programme -> program, catalogue -> catalog, dialogue -> dialog
Oh wow! Would you look at that? You can just cut off a handful of letters and just have the same word!
Thank you Noah Webster for saving us from this drivel!
America's greatest mistake
However, there is one group of changes that I strongly disagree with: the "ou" -> "o" group. This includes labo(u)r, colo(u)r, hono(u)r. From an early age I distinctly remember seeing the British spellings and thinking to myself, "Wow, we messed up on this one". Even though it is not accurate, we don't say "col-our", the British spelling does distinguish that they are two different sounds, where the American spelling discards it.
What really grinds my gears is that the American spelling strips the human element from labour and honour. Whose labour brought us all the great accomplishments of humanity? OURs! Not ORs!
From speaking with my fellow countrymen, this opinion is not widely held, but every time I have to write these words in a formal setting, I have to fulfil my patriotic duty of conforming, despite my fingers instinctively reaching for the u key, itching to press it.
Additionally there are a few words that I wish were changed to be more uniform with their other forms. The one that comes to mind is "speech". Why is it that when a speaker is speaking, that they are making a speech? Shouldn't they be making a speach?
I accept that my pet-problems with American spellings aren't ever going to result in a 2nd spelling reform movement, especially if it means bringing our spellings closer in line with that of the crown, but I do make a conscious effort to use my preferred spelling of the "ou" -> "o" group whenever possible. Text editors and word processors tend to not like my spelling of speach, and so I will concede that ground.
I shamefully admit, the British are right on this one
-
The Redesign
2026-03-23 10:40:44 PDT
Welcome one and all to the new and (arguably) improved Jasco.website!
If you haven't noticed the website looks a little bit different. Not by much, almost all the styling is identical, but if you inspect this page or any page on the site it is no longer using a separate style sheet.
You're probably thinking "why? Style sheets are fine."
It's because every page on this site is now using Notex!
"What the hell is Notex?"
What?! You don't religiously read my blog posts? As I wrote about last October, Notex is a markup language that "compiles" into HTML. In that post I detail my frustrations with both writing raw HTML markup, markdown, and LaTeX. The solution was Notex. Now you may be confused, as I said I was already using Notex for the website, which was only true to some extent. All drafts were using Notex, but as soon as anything was actually published, modifying the Notex file did nothing to affect the published page. This wasn't the end of the world, occasionally needing to pop open the HTML so I can fix a typo, but then the two files would be out of sync, bad.
This always kinda irked me, but not as much as Notex did. The fundamentals, I liked, but there were a few rough corners that I kept cutting myself on. Unfortunately, since I just hacked everything together, changing how it worked would mean rewriting pretty much everything, which I put off until a couple weeks ago.
Since I'm going to have to be referring to both the original Notex and my new rewrite, I'm going to refer to the original as "Notex 1" and the rewritten one as "Notex 2". Some of the things I changed were:
-
Functions
I really don't know what I was thinking with Notex 1's function syntax. The "/@function_name" part was fine, but using ":parameters" was plainly stupid. You should be able to pass multiple parameters without needing to ensure there isn't any whitespace in the function call. This significantly reduced the capability of functions. In Notex 2 the syntax now is a bit more in line with C style functions, using the notation "/@function_name(parameter1, parameterN-1){parameterN}".
"That's not a C style function!"
Yes, but it is closer. The first set of parameters, everything within parentheses, is used to pass actual arguments to the function, whereas the subject of the function, is generally meant for the text that is actually displayed on the page.
For instance, "/@coloredText(red){Red text}" would be the hypothetical function "coloredText", that takes the first parameter as the color and the 2nd as the text that is meant to be colored.
To me, it just makes sense that the subject is different than the rest of the parameters and thus should be isolated in the syntax.
Also I completely threw out the whole function scope idea, all functions are inline. I have yet to find a situation where I need to pass the whole document to a function and if you want the whole line to be affected by a function, you can just pass it as the subject in the new style.
-
Document <head>
Again, I don't know what I was thinking with the whole "!style=@style_name" syntax. Well, I do know that I wasn't thinking about it. I hadn't really considered how I should handle it until the last minute, and I do know the problems that resulted from this horrible design. By limiting any document to only have 1 style tag it required every CSS rule to be defined in that style function.
Notex 2 uses a separate preamble section, defined with a block wrapped in square brackets at the very top of the document. Here you can set the document title with #Title. Any HTML within the preamble gets placed in the head and any plain text is added to a meta description tag.
You could hypothetically define styling within the preamble but the better way is to use the attribute system for styling.
-
Attributes
Attributes are Notex 2's solution for styling. As a reminder, anything surrounded in curly braces is within a group and these groups can be infinitely nested. Attributes are applied at the group level. So anything within a group will have the styling associated with the attributes applied to it.
Of course there are other changes, but these are the ones that necessitated the rewrite.
While I was using Notex 1 in my day to day life, the problems previously described kept popping up. Most of them stemmed from scope creep that developed over my writing of its first iteration. I had no plans of it being used for anything besides my notes. The concept of functions didn't come to me until part of the way through development and so had always felt bolted on, but once I had them, all I could see was their potential utility. Instead of copy pasting each reoccurring element, I could simply define a function that filled in the parameters. But because Notex 1 was so janky, I never found it worthwhile to actually make them.
I was constantly fighting with the early design decisions I had made, needing to be modifying the compiled HTML document to fix the errors that arose from edge cases I hadn't imagined. Fortunately, it made writing Notex 2 far easier, because I already had a solid grasp of the problems that could arise.
While adapting my website tooling to take advantage of Notex 2, I adopted a radical approach. Instead of building the tooling to work cohesively with my back catalog of previously made posts, I built my desired writing flow. I got it to the point where I now should not have to open up the compiled HTML. The "template" directory is where all the Notex files live. This is then mirrored in the "published" directory. The compiled HTML is output to the "published" directory and any other files are copied over into their respective subdirectories.
Only once I got this working did I then start adapting my previous posts to use the new format. This was fairly easy since raw HTML can be embedded in a Notex document and will just be passed through in compilation. All it meant for most of them was stripping the header and footer and replacing them with the newly defined functions. Now if I ever want to update them, all I have to do is just modify the function and recompile all the pages.
After such a long time I'm looking forward to writing posts without needing to worry about fighting with janky software.
-
-
Burnout
2026-02-23 14:29:23 PST
Senioritis + Job Woes = one unhappy camper
As I've mentioned multiple times, I do not like my job. At least once a month I go scrolling through job listings looking for the next thing.
I'm also on the 12th and final semester of my 8 semester long CompSci undergraduate degree. I could write a dissertation on how much of this was not entirely my fault and how much of this was caused by systemic inefficiencies in the university, but I'll save you from that whining this time.
No, today I want to complain about burnout.
School
It's been about a year since I've liked any of my classes. I was thinking that finishing up all the general education requirements would let me get more deeply involved in my studies, especially when it is in subjects I am interested in, but it's had the opposite effect. I'm longing for the days of having my head pushed under the waters of an unfamiliar stream in the river delta of human knowledge. While some of those courses also caused the same pangs of burnout, many of them also served as a nice break from the unending flow of clever ways we've tricked transistors into doing math for us. One of the major reasons is that I'm deeply uninterested in the electives I'm taking.
Ok I lied, I'll do some whining about the systemic issues of the university, as it is necessary to understand the context. My school's CompSci classes fill up in the blink of an eye due to there being a major discrepancy between the number of sections taught and the number of students, with the latter dwarfing the former. There exists a program for students who are the first-generation going to college or are part of a minority group which allows them to get earlier enrollment dates as well as special advising. On paper this sounds great and something I would support, the problem is that my school is majority-minority, even more so in the CompSci classes. While not everyone is part of the program, a large enough portion are, so much that days before I'm even allowed to sign up for classes, they're already filled with a maxed out waitlist. Of course I don't hold any animosity towards the program members, hell most of my friends are in it, but it knocks the wind out of your sails when it feels like your university doesn't want you to graduate.
Last semester, I only had two classes on the first day, requiring me to make a mad dash to any classes that were notoriously, frequently dropped, whether it be for their difficulty or poor quality of professor. That's how I got to sit through the confused ramblings of a geriatric, over indecipherable slides that only served to confuse even relatively basic concepts. The subject matter need not apply, the man could have been teaching a course on the order of the planets and I would have come out less sure of the position of Mercury for every lecture I attended (which was not many).
The second class was run by a man that would have made der Fuehrer blush; so enraged by the scourge of grade inflation, that the most dedicated students are lucky to pass with a C, also a total prick. Fortunately I was able to drop him after a couple weeks as I was able to secure a spot in a GPU Accelerated general computing course. This professor was decent, with reasonable homework and solid lectures, but the subject-matter was nevertheless difficult. I wanted to avoid the mad scramble again and bugged the advisor's office until I had all my final requirements fulfilled and wouldn't have the mad dash again...
Work
The semester starts a bit earlier for work, we're on our fourth week, but only now is the torrent of tickets starting to trickle. This cohort is rowdier than previous ones and I've had more people screaming at me over the phone than previous semesters. Last week a guy called us and kept shouting about how he felt scammed, that all we did was take his Pell grant and left him with classes he couldn't attend because our software doesn't work. I didn't have anything to tell him, because I know that's exactly how the business worked.
I hated the feeling of leaving work every day hating the company even more than the last. I remembered the feeling all too well, it was exactly like my last few weeks working at the store, the malice and resentment building up before it boiled away with my resignation letter, one I hope to be turning in soon.
Conflict
So that takes us to last week (5 weeks ago now), the start of my school in phase with a busy period of work. My entire schedule was meant to be online, so at least I wouldn't need to actually get up and go anywhere besides the office in the evening. I read through the syllabus of one of my courses, one that I was told was online and asynchronous, only to find out that I was mistaken, yes it was online, but it was very much synchronous, and right in the middle of my shift. Now it would be one thing if I needed to get into work a little late, I've had to do that a couple times for afternoon classes, but smack dab in the middle of our busiest time of the night wouldn't fly, and even if it did, I didn't provide any notice because I was told it would be asynchronous!! Could I have probably made something work with my boss? Yes, but at this point I was itching for an excuse to leave.
So I asked for my job back at the store.
They were hiring and the manager would have hired me on the spot if it were fully up to him. We left on good terms. I walked out of the store feeling somewhat relieved, once I got the approval from the owners of the store I was going to put in my two weeks and fall back to an old routine, from a time where I was truly happy doing something I felt good about.
As I drove to work, some pangs filled my head:
"You'll need to work weekends"
Ok yeah, that kinda blows not having your 2 days off sync up with the rest of the world, but I'd have my evenings back. No more needing to get home late every evening.
"But what about those weekend trips to go see your girlfriend in Washington"
Oh shit, right, she can't just take time off to sync it up with my schedule and the long weekends where the store is most busy...
"You'll need to buy an Apple computer"
Why?
"You Facetime her on your work laptop all the time and need something for OpenBubbles verification"
Oh right... Well how much would a beat up M1 Mac cost anyway?
"But you're making less money"
Only if I work the same hours!!
"So you want to pick up a job where you have to work more doing a harder task because?"
It's closer to home and so I'll save money by riding my bike, and it's right next to the grocery store so I'd be incentivised to cook more!!
"Sure buddy, you say that every time"
Then, an email arrives in my inbox
ACCEPTED: ADD FORM FOR CLASS CS XYZ
Oh. So there's no more problem?
Then actual relief went through, not the faux relief I wanted to feel walking out of the store asking for my job back. I knew what it meant. I wasn't leaving.
So now I have it all, the classes I need to graduate, a flexible enough job that I can spend money on things I enjoy and people in my life, everything should be dandy.
But it's not.
I feel stuck in a state of impermanence. Stuck in classes I couldn't care any less about, stuck at a job I actively despise, stuck in a state that no longer feels like home. I want to start packing for Washington, but know that it's too early. I want to start applying to real jobs but know that I don't yet have the degree. I want to learn but I already know the material covered in class.
It's just hard, I'm so ready to take that next leap, I'm 95% of the way there, the finish line is in sight, I just have to wait and keep my head above water.
And I miss my girlfriend a lot. I didn't realize how much those little walks sipping our chai lattes made the days so much more bearable. Bless the telephone, but it's no replacement for having her here.
At least I have that weekend a month up there with her to look forward to.